
数仓分层设计.jpg
表命名通用规范:层级前缀_主题域_表内容
- dwd层,该层的粒度一般保持和ods层一样,不过有时为了数据开发时易用性,会退化一些维度进入事实表,减少事实表和维表的关联提高性能。通常是解析ods层日志数据或者对ods层业务数据进行维度建模。
提供数据质量,做一些数据清洗的工作,比如去噪或去异常值。 - dwm层,主要作用有2种:①对dwd层的数据按照维度进行收敛,做明细数据轻度聚合,出现一些业务统计指标。②把各个业务相关的可归为同主题的dwd表关联一起组成宽表获取更丰富的字段信息,使用宽表模型,做明细数据横向整合。
- dws层,在这层的数据表会比较少,根据业务线划分生成字段较多的宽表,比如充值统计、活跃统计,一般是多天累计的分区表,出现一些比如近30天的充值次数啊等指标。这层重点在于提高数据易用性,起数据开发优化作用。
四、几种常见数据模型
- 星型模型
是数据集市维度建模中的推荐方法,星型模型以事实表为中心,所有的维度表都直接连接在事实表上,像星星一样,按维度进行汇总,所以执行效率会比较高些。维度建模的领域主要适用于数据集市,它的最大作用其实是为了解决数据仓库建模中的性能问题(join少则shuffle就少,性能就越好),维度建模很难能够提供一个完整地描述真实业务实体之间的复杂关系的抽象方法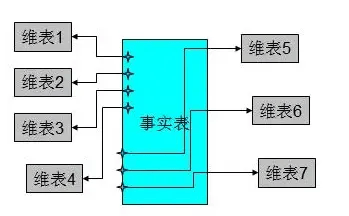
维度建模
- 雪花模型
雪花模型的维度表是可以拥有其他维度表的,图示的话就是不用直接连接在事实表上,不过也没有严格遵循三范式,性能比星型模型低,但相对较灵活些 - 范式模型
范式模型介于星型模型和雪花模型之间,优点是避免数据冗余 - 星座模型
星型模型的扩展,只不过星座模型是可以基于多张事实表的,可共享维度信息。数据仓库大多是这类模型,即数据集市建模采用星型模型,然后各数据集市组成一个完整的数据仓库则演变成星座模型
五、数据仓库建模
数仓构建一般还是采用维度建模的方式。
1、维度建模
维度建模四步走如下 (PS:按流程走,四步是从上往下,环环相扣的)
-
1、选择业务过程
此过程是基于业务需求以及日后的易扩展性考虑的,即开始数仓建模时按业务区分选择数据。 -
2、声明粒度
存在一对一关系的就是相同粒度,粒度可以理解为层级,比如一个公司有多个部门,一个部门有多个员工,而这里面的不同部门就是相同粒度,不同员工也是相同粒度。维度建模时在同一事实表中必须具有相同的粒度,不同粒度最好建立不同的事实表,从业务获取数据时最好是从最细粒度开始,即原子粒度。 -
3、确认维度
维度就是分析数据的角度,是数仓的“灵魂”,数仓工具箱告诉我们牢牢掌握事实表的粒度,就可以区分出维度,维度表必须保证不出现重复数据,即维度唯一。 -
4、确认事实
事实表是用来度量的,基本是一些计数值,维度建模核心原则之一是同一事实表中的所有度量都必须具备相同的粒度,才能确保不出现重复计算度量的问题。
附学习参考文章:https://www.cnblogs.com/itlz/p/14262577.html
2、范式建模
主要应用于数据库设计,通过三范式对表进行设计,避免数据冗余。
3、关系建模
严格遵守三范式对表进行设计,避免数据冗余和保持数据一致性,关系建模和维度建模在表关系依赖方面基本相似,维度建模一般只依赖一层表关系,关系建模就会层层表依赖,关系表比较多,关系复杂些。
七、历史拉链表刷新策略方法
涉及全量初始化、增量抽取进表并刷新历史数据:http://lxw1234.com/archives/2015/08/473.htm
数据仓库之ETL策略:http://lxw1234.com/archives/2015/04/31.htm
八、数据仓库的常见指标计算
留存用户计算:计算思路就是通过取一时间段内的用户进行与统计当天用户关联,如果关联上则表示仍是之前的用户,那个用户即为留存用户。
新增用户计算:前提是拥有一张全量历史表,每天新增的用户往里面刷新,历史的数据也保留着,计算新增用户则把统计最新一天的用户捞出来即可
累计用户计算:同上,前提是拥有一张全量历史表,每天新增的用户往里面刷新,历史的数据也保留着,计算累计用户则把历史全量的用户捞出来
评论列表